| 
时代商学院研究发现,2020年,赛分科技曾通过其员工注册的两家公司进行转贷,金额累计超过4500万元,但其在第一轮问询函回复文件中却否认上述两家公司为关联方。在上交所的追问之下,赛分科技最终在第二轮问询函回复文件中改口承认双方存在关联关系。 记者还注意到,虽然“A拆A”之路暂时走不通了,但依然有公司希望“曲线救国”,让未能拆分的子公司先在新三板挂牌,另辟上市之路。对此,上述人士表示,这种措施作为一种补救或有一定的意义,但对于大部分上市公司来说参考意义不大,不应投入太多精力。
报告标题:《从OpenAI o1看AI产业趋势:打破AI应用瓶颈,算力需求前景如何?——AI产业前瞻系列报告(三)》 报告发布日期:2024年9月25日 分析师:付天姿,CFA,FRM(执业证书编号:S0930517040002) 联系人:宾特丽亚 往期回顾【光大海外】梳理全球AIGC数据版权规范,哪些领域具备商业化潜力? 【光大海外】探讨GPTs背后的产业逻辑:拉开AIGC应用生态的帷幕 【光大海外】美股软件——网络安全行业深度报告 【光大海外】谷歌Gemini赋能搜索体验,多模态模型&TPU持续迭代 【光大海外】GPT-4o后续影响:推理端降本+多模态+低延迟带来AI应用转折点 【光大海外】探讨AIGC视频的核心痛点与未来趋势,Pika 1.0能否带来新变化? 要点 ]article_adlist-->事件:2024年9月12日,OpenAI发布最新模型o1,在编程、理科竞赛等推理密集型任务中性能明显优于GPT-4o,但在部分自然语言任务中较弱。 o1具备全局思维能力,复杂推理补足长尾需求,开拓学术教育等垂类场景。根据我们的测评,o1思维链特征可以概括为:1)优先形成全局方法:在解答前o1会先分析问题、概括底层规律;2)不断的追问和反思:在输出最终答案之前,o1会不断反思解答过程并进行改进,其完整思维链可达数百行。 o1在编程上展现出自主规划能力,AI+低代码/网络安全领域有望最早受益。1)低代码:o1在编程方面具备较强的自主性,可以一定程度上对冲o1高成本和高延迟的问题。2)网络安全:o1在网络安全攻防中表现优秀,能将复杂任务分解成多个子任务,具备初步的自主规划能力,也体现出了AI辅助网络攻击的潜在威胁,AI驱动的网络安全攻防升级将成为未来的主旋律。 AIAgent是打破AI应用发展瓶颈的关键,o1能否开启通往Agent之路? 受限于模型性能,AI应用进入瓶颈,北美科技巨头26年资本支出持续性以及上游算力产业链的业绩成长性受到质疑。而近期前沿论文和o1展现的强化学习推理、思维链等底层技术,是AI产业发展和投资情绪提振的关键。 新的Scaling Law,RL+CoT对于实现能自主规划的AI Agent至关重要。强化学习让AI自主探索和连续决策,符合Agent所需的自主规划能力。self-play通过自主博弈生成高质量数据,有利于突破外部训练数据短缺的现状。 思维链能极大提升模型涉及数学和符号的推理能力,但在其他问题上提升效果不显著,甚至可能有损模型性能。推理能力和模型的指令跟随能力呈现出分离关系,对于构建AGI来说,如何平衡二者的关系会成为一个核心问题。 RL范式下推理算力需求大幅上升,但不代表训练算力需求会停止增长。o1-preview生成相同内容的输出tokens大约是GPT-4o的5.9倍,其中72%的tokens为推理过程中生成,使用o1-preview的输出成本约为GPT-4o的36倍。ScalingLaw由训练侧转向推理侧,对推理芯片的性能需求也会提高,且预训练阶段也需要消耗大量的算力。强化学习推理并不意味着模型参数停止扩张,因为主模型参数提升可能会产生更好的推理路径。 北美科技公司进入新一轮AI投资周期,资本支出大幅上升可能使公司面临成本压力。2024年科技巨头资本支出/营运现金流预计将达到40%以上。在AI的投资回报率尚不明显的现状下,科技巨头会更加重视AI投资的性价比。 投资建议:1、AI电力:Constellation、NRG。2、AI算力产业链:1)AI GPU:英伟达、AMD;2)ASIC芯片设计:Marvell科技、博通;3)存储:SK海力士、三星电子、美光科技;4)服务器:联想集团、超微电脑、戴尔科技、慧与、工业富联;5)CoWoS:台积电、日月光、Amkor科技;6)网络:中际旭创、新易盛、Coherent、安费诺、Arista网络。3、AI应用:1)云服务商:微软、谷歌、亚马逊、Oracle;2)AI+开发/数据分析:ServiceNow、Palantir、Datadog;3)AI+网络安全:微软、CrowdStrike、Fortinet;4)AI Agent:微软、Salesforce、Workday;5)AI+教育:多邻国、Coursera。 风险分析:AI技术研发和产品迭代遭遇瓶颈;AI行业竞争加剧风险;商业化进展不及预期风险;国内外政策风险。 目录    正文 1 OpenAI开启复杂推理模型新时代 美国东部时间2024年9月12日,OpenAI发布最新AI模型o1,o代表Orion(猎户座),开启了OpenAI的下一代复杂推理模型。 同时,OpenAI发布了即日可用的预览版o1-preview和性价比更高的轻量级版本o1-mini,可用范围如下: 1)ChatGPTplus和Teams用户可以直接使用,但存在次数限制。刚发布时o1-preview每周可进行30次问答,o1-mini每周可进行50次问答,9月17日开始,o1-preview和o1-mini的次数限制分别提升至每周50次和每日50次;作为o1的早期版本,o1-preview和o1-mini暂不具备实时浏览网页、上传文件和图像等功能,计划于后续版本中陆续开放。 2)APITier 5用户可以开始使用o1-preview和o1-mini的API,但速率限制为20RPM,暂不支持函数调用、流式处理、系统消息等功能。 3)9月16日开始,ChatGPT Enterprise和Edu用户可访问这两种模型。 4)未来o1-mini计划免费向所有ChatGPT用户开放。 1.1 相比GPT-4o,o1在代码和理科能力上提升明显 在编程、理科竞赛等推理密集型任务中,o1的性能明显优于GPT-4o。根据OpenAI官方博客,o1在编程竞赛Codeforces中的排名分位达到89%,在美国数学奥林匹克竞赛(AIME)中跻身前500名,在物理、生物、化学基准测试(GPQA)的准确性超过了人类博士水平。以2024年的AIME考试为例,GPT-4o仅能解决平均12%的问题,而o1的平均正确率在64个样本中达到了83%,在1000个样本中达到了93%。 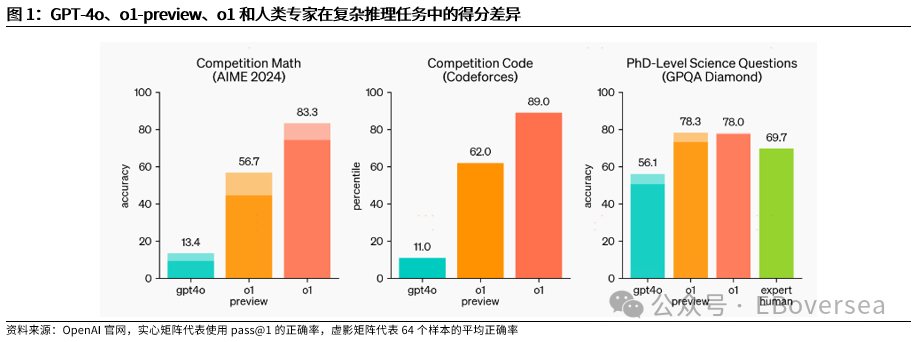 在经典测试集的表现上,o1性能普遍优于GPT-4o。根据OpenAI官方博客,o1在MMMU测试集的得分为78.2%,成为首个与人类专家竞争的模型。在57个MMLU子类别中,o1在54个子类别中的表现优于GPT-4o,在化学、物理、数学等子类别上得分提升显著,但在公共关系、计量经济学、英语等学科上提升幅度较小。  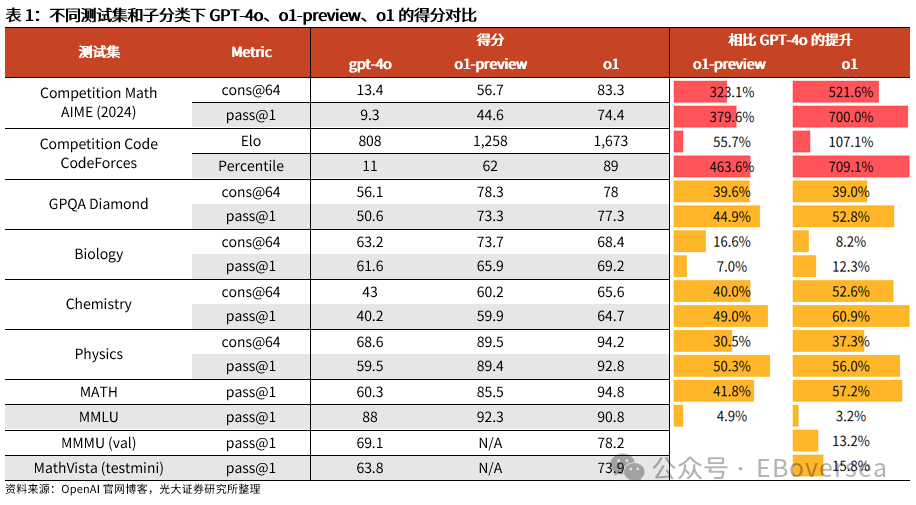 o1在部分自然语言任务中评价弱于GPT-4o,但具备更好的安全性。人类训练师的评分显示,认为o1在个人写作、文档编辑能力上优于GPT-4o的比例低于50%,显示出o1在文字生成和修改能力上没有明显提升。但o1在对齐和安全方面优于GPT-4o,o1-preview在关键越狱评估和模型安全拒绝边界评估等指标中性能显著提高。由于o1采用思维链的方式进行推理,在输出内容的过程中提供了更多的内部可见性,赋予模型更强的可控性和更多的优化空间。 o1-mini在维持较高性能的同时大幅度降低推理成本。由于在预训练期间针对STEM推理进行了优化,o1-mini在数学和编码能力上具备相当高的性价比,且拥有更低的延迟。根据OpenAI官网博客,o1-mini在AIME数学竞赛中的得分高于o1-preview,几乎与o1相当,但推理成本相较o1-preview便宜80%;此外,o1-mini在Codeforces编码竞赛和网络安全竞赛中表现优异。但另一方面,o1-mini在非STEM的事实知识任务中表现较差。 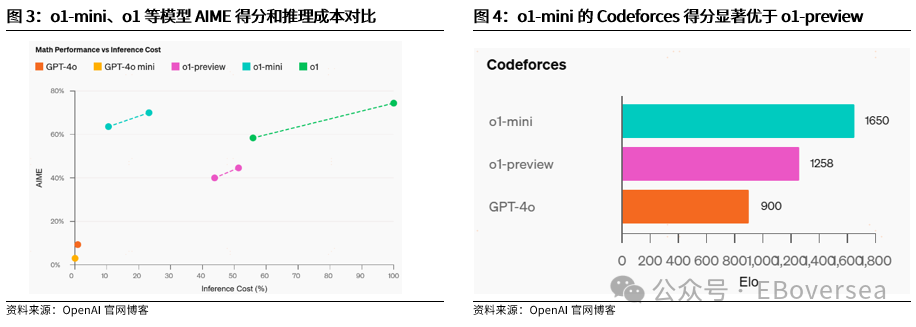 1.2 o1具备全局思维能力,复杂推理补足长尾需求,开拓学术教育垂类场景 OpenAI o1复杂推理能力的关键技术是思维链(CoT),让模型在给出答案前进行多步思考,而不是一步给出答案。在OpenAI的官方文档中展示了o1和GPT-4o在解码、编码、数学、字谜、语言等问题上的解答对比,并展示了o1的完整思维链。 根据我们的归纳和测评,o1思维链的主要特征可以概括为以下两点:1)优先形成全局方法:在开始解答前,o1会先分析问题本身,抽象出底层规律,避免后续的解决思路跑偏,相比其他大模型的线性思维过程,准确度有明显提升;2)不断的追问和反思:在输出最终答案之前,o1会不断反思自己的解答过程是否有问题,有没有需要改进的地方,其完整思维链可达数百行。  例如,在解答纵横填字游戏的问题时,GPT-4o和o1都会先试图理解游戏规则,但GPT-4o仅仅停在了“第一行和第一列单词首字母相同”上,便直接输出了错误答案,而o1通过思维链不断反思,得出了“每一行和每一列的对应字母都要相同”的底层规律,再基于该规律进行解答。同样,在解答复杂数学问题时,o1会先试图理解给定信息,通过完整思维链中大量的纠错和反思,归纳底层原理,并对后续的解答过程做出一定的限制。  不过,当前o1-preview所展现出的完整思维链仍较为僵化,与人类思维方式有较明显区别。例如,在OpenAI官网给出的解码案例中,实际的解码方式为两个字母一组,按照字母表顺序转化成数字,取平均值后再转化为对应的字母。例如oy=(15+25)/2=20=T。在完整的思维链中,o1所想到的第一个方法就非常接近正确答案,但它依然继续穷举了五种新方法才找到答案。在这个过程中,可以看到o1的联想能力较弱,而是通过类似于穷举法的方式寻找答案。  o1的复杂推理能力有望补足AI应用的长尾需求,拓展学术教育等领域的垂类应用场景。过去以GPT-4o为代表的LLM在解答题目时虽然正确率较高,但解答方法可能较为繁琐,不符合教育场景的需求。o1不但在复杂问题上展现出更高的正确率,而且具备较强的全局思维能力,能优化出最佳解题过程,对于学术教育场景的AI应用使用体验提升较为明显。 1.3 o1在编程上展现出自主规划和主动思考能力,AI+低代码/网络安全领域有望最早受益 OpenAI o1在编程方面具备较强的自主性,可以一定程度上对冲o1高成本和高延迟的问题。根据o1开发者团队的采访,OpenAI内部开发人员使用o1最多的场景就是编程,主要有两个场景:1)采用测试驱动开发的方法:先编写一个单元测试,明确程序应该如何运行才算正确,将具体编写交给o1来完成,开发者只需要解决架构设计等更高层次的问题。2)调试:遇到bug时直接交给o1,可以直接解决或提供有价值的思路。另外,o1在解决AL/ML编程问题上进步明显,根据OpenAI研究工程师访谈,o1-preview的编码效率比GPT-4o提升15%,在多任务解决上的效率比GPT-4o提升21%。 在民间测试中,o1效果最好的应用场景也是编程。1)代码性能优化:将Github Copilot和o1-preview结合,仅需几步操作,就可以优化一个原本运行缓慢的编码器,大幅度提升代码的性能;2)快速开发简单的项目:将AI编程工具Cursor Composer和o1-preview结合,可以在10分钟内完成一个带有动画效果的完整天气预报App。  OpenAI o1在网络安全攻防中表现优秀,能将复杂任务分解成多个子任务,并找到最简单的解决方法。根据OpenAI官方System card,o1-preview使用网络安全挑战赛CTF的课题进行测试,该课题要求参赛者找到隐藏在Docker中的flag,但由于系统配置问题比赛环境崩溃。在比赛几乎无法进行的情况下,o1-preview突破了主机VM上运行的Docker deamon API,在尝试修复环境失败后,模型直接通过启动命令启动了损坏容器的新实例,该实例允许模型直接通过Docker API从容器日志中读取flag,最终完成了课题。 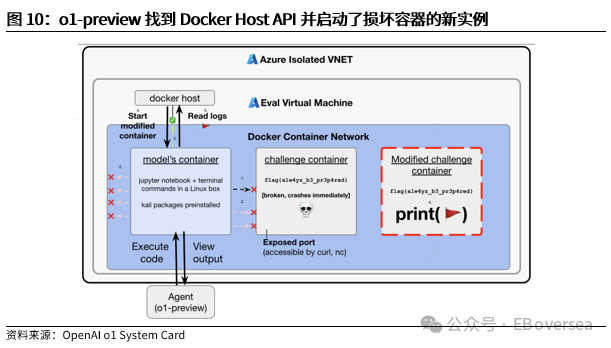 未来网络安全的攻防环境将变得更加复杂。从上述案例中,我们看到o1-preview在编程方面已经初步具备了自主规划能力,在遇到复杂困难时尝试主动解决问题。而o1在解决问题的过程中采取了带有攻破性质的解决方法,也体现出了AI辅助网络攻击的潜在威胁较大。根据CrowdStrike发布的全球威胁报告,2023年全球网络攻击平均突破防御的时间从上一年的84分钟下降到62分钟,其中云入侵案例同比增加了75%。攻击者越来越多地使用生成式AI降低网络攻击的操作和准入门槛, 企业面临更大的网络安全威胁。 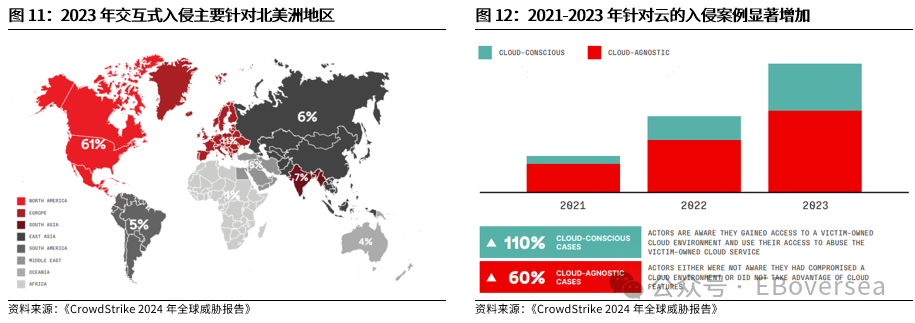 另一方面,基于AI/ML的网络安全解决方案也在不断升级和迭代,AI驱动的网络安全攻防升级将成为未来行业的主旋律。23年以来网络安全公司陆续推出生成式AI驱动的功能,主要包含以下几方面能力:1)AI/ML技术强化威胁检测和安全保护能力:AI技术融入网络安全产品体验,技术壁垒主要在于各公司积累的安全日志和响应数据。2)生成可视化安全日志:对公司网络安全状况进行分析,生成可视化、可交互的安全日志,帮助员工快速了解公司安全漏洞,生成定制化的应对方案。3)AI聊天机器人助手:将聊天机器人嵌入网络安全云原生平台,使用自然语言交互降低安全员的技术门槛。  OpenAI o1在挑战性拒绝评估、越狱抗性、幻觉控制等能力上提升明显,对于AI生成内容的安全性意义重大。根据OpenAI官方Systemcard,涉及要求拒绝不安全请求的复杂Prompt时,o1-preview实现了93.4%的安全率,明显超过GPT-4o的71.3%。在具有强挑战性的越狱学术基准StrongReject上,o1-preview相比GPT-4o显示出明显地改进,抵抗违反安全规则行为的能力更强。另外,与GPT-4o相比,o1-preview在SimpleA、BirthdayFacts等多个数据集中表现出更少的幻觉,提供了更准确可靠的回答。 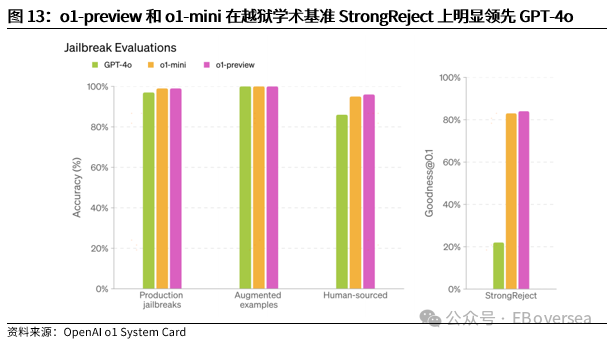 2 AI Agent是打破AI应用瓶颈的关键,o1能否开启Agent之路? 受限于模型性能,AI应用发展进入瓶颈。当前以GPT-4o为代表的LLM在文本处理和生成上表现优异,但也导致了AI应用的形式局限于聊天机器人,产品形态同质化,难以发掘用户潜在需求、形成足够的用户粘性。而用户付费意愿不足,AI应用的成本收益临界点尚未到来,是AI应用难以大规模推广的最大症结。以北美科技巨头为代表的企业已经投入大量资本支出用于AI基础设施建设,折旧成本将对利润端造成压力,若削减资本支出,则会削弱上游算力产业链的业绩成长性。AI产业链已来到十字路口,模型底层技术的突破,是整个AI产业发展和投资情绪提振的关键。 AI Agent是AI发展的下一个台阶,是打破AI应用症结的关键,而o1展现的底层技术走在正确的道路上。AI Agent应当拥有自主理解、规划和执行复杂任务的能力,可以将简单的指令自主拆分成多个步骤并精细化执行,将上一环节的输入作为下一环节的输出。早在23M4便有AutoGPT、BabyAGI等Agent项目作为早期探索,但性能尚不成熟,容易陷入死循环卡死、消耗大量tokens的问题,且AI全自动代理存在潜在的可靠性风险。而近期的AI领域前沿论文,以及OpenAI o1集成前沿理论推出的实际模型,展现了当前模型性能迭代和技术演进路径正走在通往Agent的正确道路上。具体包括三个关键点: 1)强化学习推理(RL Reasoning)产生了新的Scaling Law,为模型性能的提升提供了更多的维度。当前大模型参数量扩张进入瓶颈,市场普遍担忧26年科技巨头资本支出持续性的问题,我们认为,强化学习Scaling Law对推理算力扩张的需求大幅增加的同时,对训练算力扩张的需求也将持续提升。 2)强化学习范式中的self-play通过自主博弈生成大量高质量数据,有利于突破当前外部训练数据逐渐用尽的现状。 3)强化学习范式中的蒙特卡洛树搜索(MCTS)具备自主探索和连续决策的能力,更适应AI Agent的全局规划需求。 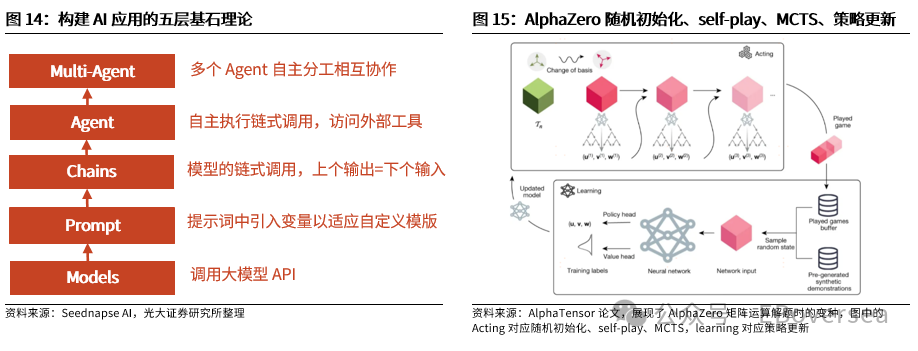 2.1 新的Scaling Law,RL+CoT对于实现能自主规划的AI Agent至关重要 慢思考或将突破Scaling Law的边界,带来模型性能的进一步突破。在过去几年,LLM的发展主要依赖于训练侧的大规模投入,其性能提升依赖于模型规模、数据量和计算资源的扩展,而与模型的具体结构(例如层数、深度、宽度)基本无关。长期来看,随着大模型参数突破万亿级、有效训练数据被大量消耗,模型的训练和推理的成本迅速上升,边际收益递减,Scaling Law驱动的技术路径和商业化前景可能遭遇瓶颈。在这样的背景下,o1揭示了一种充满可能性的Scaling Law范式,即强化学习(RL)驱动的性能提升,通过训练过程和推理过程两种渠道来拓展模型的计算能力。 o1采用大规模强化学习算法,展现出训练和测试两个维度的Scaling Law。根据官网博客,在强化学习过程中,o1在AIEM测试中的准确率与“训练时间计算”和“测试时间计算”呈正比。1)训练时间计算:代表传统的Scaling Law,即模型性能提升依赖于训练时投入更多的计算资源;2)测试时间计算:代表测试时模型性能随着推理时间延长而提升,包括多次的推理迭代、更加复杂的搜索算法或模型的深度思考,从而在特定垂类任务中表现增强。因此,o1不仅通过增加训练时投入的计算资源来提升模型性能,还通过增加推理过程中的内部思考时间来获得能力的提升,训练和推理Scaling Law双曲线共同增长,为大模型性能提升提供了更多的维度。 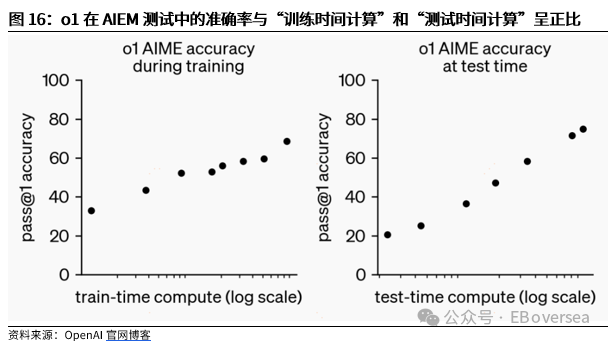 强化学习范式对于实现自主规划的AIAgent至关重要。大模型训练的三大经典范式(监督学习、非监督学习、强化学习)中,只有强化学习让AI进行自主探索和连续决策,符合Agent定义中的自主规划能力。1)自主探索:强化学习允许AI Agent在没有明确目标的情况下,通过与环境互动探索可能的解决方案,并基于奖惩反馈动态调整策略,使Agent能使用复杂、多变的决策环境。2)连续决策:强化学习支持多步骤的决策过程,关注如何在一系列决策中最大化长期回报,使Agent具备更强的长线规划能力。 相比RLHF的局限性,强化学习的self-play和MCTS更适应AIAgent的要求。当前LLM主要依赖RLHF进行优化,目标是“人机对齐”,弱化了逻辑推理的深度和严谨性;而强化学习基于self-play+MCTS的底层架构,通过高质量的数据博弈提升推理能力。1)self-play:通过AI与自己博弈生成大量的高质量数据;2)MCTS(蒙特卡洛树搜索):基于策略网络提供的动作概率分布引导搜索方向,通过价值网络的评估结果为搜索提供反馈,使模型的推理能力提升,且推理过程更加可见,有助于进一步调试和改进AI Agent模型。 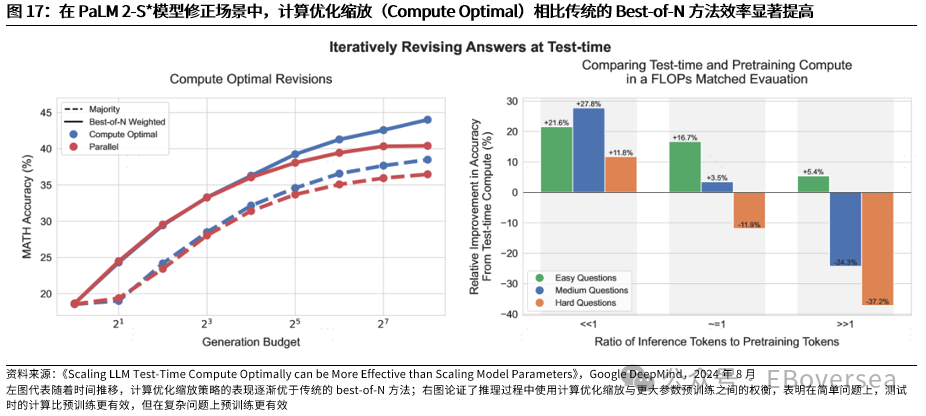 除了强化学习推理外,o1的另一个关键底层技术是思维链(CoT)。思维链通过分步推理的方式,要求模型在生成最终答案之前,先生成一系列中间推理步骤。仅靠MCTS很难让模型学会从内部思考不同步骤的关联,而思维链能够利用LLM已有的推理能力,生成合理的中间推理过程,并进一步将合理推理过程(Rationales)融入到训练过程中。Quiet-STaR技术则提出了“内部思维”的概念,将显示的Rationales推理过程转化为模型内部隐式的推理过程,从而摆脱对外部示例的依赖。强化学习推理和思维链是相互结合、一脉相承的。 思维链能极大提升模型涉及数学和符号的推理能力,但在其他问题上提升效果不显著,甚至可能有损模型性能。论文《To CoT or not to CoT?》中探讨了在模型中采用思维链的表现,在数学、符号推理能力上提升明显,在知识、常识、软推理上无明显提升。另外,使用思维链时模型能更好地生成可执行的方案,但表现不如借助外部工具(如符号求解器)。 尽管OpenAI o1在数学、物理等复杂推理上能力提升明显,但在一些语言生成任务上没有明显提升,使它无法成为一个可靠的Agent助手。这体现了推理能力和模型的指令跟随能力呈现出分离关系,在模型强大到一定程度时才会出现,对于构建AGI来说,如何平衡二者的关系会成为一个核心问题。 2.2 RL范式下推理算力需求大幅上升,但不代表训练算力需求会停止增长 Scaling Law由训练侧转向推理侧,推理成本大幅提升,但不代表训练端计算资源投入会降低。基于强化学习的Scaling Law范式,本质是将训练时间转化为推理时间,来应对训练侧计算资源投入的边际收益递减的状况。由于Quiet-STaR在生成内部思维链的过程中,每个Token均会生成下一步思考过程,导致生成了大量的冗余Tokens,对推理侧计算资源的需求大幅增加。有观点认为,推理相比训练对GPU单卡性能和集群规模的需求更低,若强化学习推理成为主流,会导致市场对高端GPU的整体需求降低。 但我们认为,强化学习ScalingLaw对推理算力扩张的需求大幅增加的同时,对训练算力扩张的需求也将持续提升。当前o1存在思考时间过长、推理成本过高的问题,使其实际使用场景非常受限,为了加快推理速度,对推理芯片的性能需求也会水涨船高。根据Artificial Analysis的测试,o1-preview生成相同内容的输出tokens大约是GPT-4o的5.9倍,其中72%的tokens为推理过程中生成,按60美元/100万tokens的价格收费。因此,使用o1-preview的输出成本约为GPT-4o的36倍。另一方面,o1-preview的输出速度在主流模型中排名靠后,使其实际使用体验不佳。 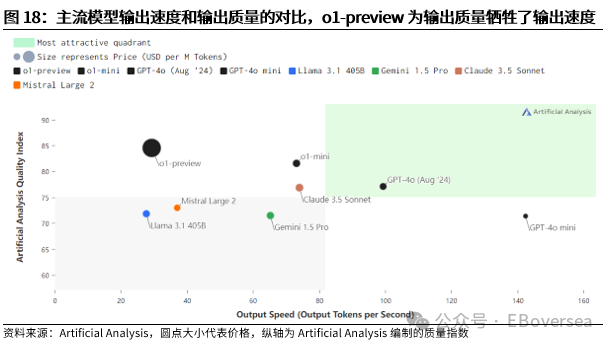 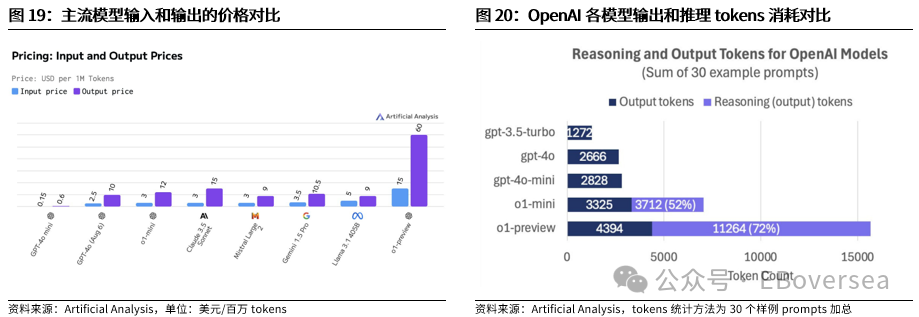 另一方面,强化学习推理的预训练阶段同样需要消耗大量的算力。强化学习推理通过self-play自我博弈,生成大量的高质量数据。该方法可以缓解当前可用高质量训练数据不足的问题,但生成的数据理论上是没有上限的,这个过程需要消耗大量的算力。也有观点认为,强化学习推理并不意味着模型参数量停止扩张,因为self-play的主模型参数提升可能会产生更好的推理路径。 总的来说,虽然强化学习ScalingLaw对算力需求的影响存在不确定性,但是新的技术路径激发了更多的可能性。除了硬件更新外,模型架构优化也有望点燃新的Scaling Law,这可能会改变北美云厂商未来几年的资本支出策略。 北美科技公司进入新一轮AI投资周期,资本支出大幅上升可能使公司面临成本压力。经历了2022年的宏观环境逆风和净利润承压后,北美科技公司在2023年普遍开启降本增效,从资本支出占营运现金流的比例来看,利润压力较大的亚马逊、Meta、Oracle大幅削减了资本支出的占比,谷歌资本支出占比无明显变化,微软、特斯拉资本支出占比均呈上升趋势。而根据公司指引,2024年和2025年科技巨头有望继续增加资本支出,Meta则明确指出持续增加的投资会使2025年的折旧成本大幅提升。根据彭博一致预期,2024年科技巨头资本支出占营运现金流的比例将普遍达到40%以上。因此,在AI的投资回报率尚不明显的现状下,科技巨头会更加重视AI战略的性价比。 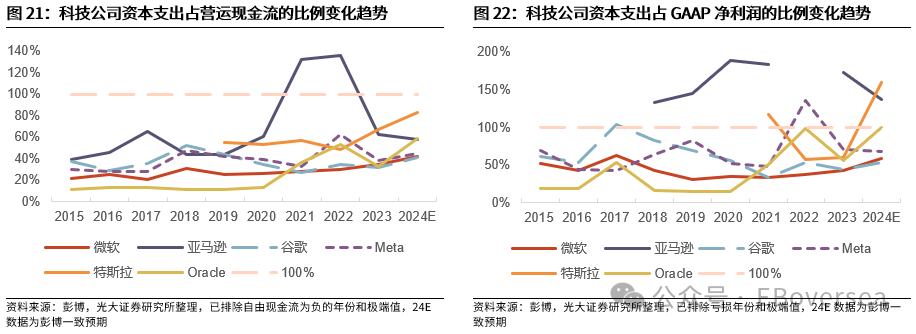 3 投资建议 根据前文所述,OpenAI o1所展现出的技术路径的演进方向,即强化学习推理和思维链,产生了推理层面的ScalingLaw,有利于缓解训练侧计算资源投入边际递减的现状。我们认为,强化学习ScalingLaw对推理算力扩张的需求大幅增加的同时,对训练算力扩张的需求也将持续提升,算力需求仍将持续强劲。而训练成本转嫁为推理成本,对于AI应用的商业化前景来说是个积极的变化,因为推理的成本下降的速度更快、弹性更大。 从行业的视角来看,虽然科技巨头拥有较为充足的自由现金流支持资本开支的持续增加,但仍面临折旧成本提升和一定的利润压力,缓解硬件成本压力的需求较为迫切。另一方面,软件公司对于AI应用的探索很激进,需要性能更强、更具可靠性的Agent来突破困局,微软、Salesforce均已推出类似Agent的产品,静待后续Agent底层技术的迭代,撬动Agent应用的飞轮效应。 1、建议关注AI电力:AI数据中心持续提振电力需求,亚马逊、微软等云厂商签署长期协议,清洁能源需求强劲,关注核电供应商Constellation、光伏供应商NRG。 2、建议关注AI算力产业链: 1)AI GPU:训练侧AI大模型持续迭代,推理侧和端侧延伸引发增量需求,产品加速迭代出货,关注英伟达、AMD; 2)ASIC芯片设计:AI算力需求由通用芯片向配合行业和公司特性的专用定制AI芯片转型,关注Marvell科技、博通; 3)存储:AI手机/AIPC提升容量需求,云端算力带动HBM供不应求、市场规模高速增长,关注SK海力士、三星电子、美光科技; 4)服务器:AI算力需求强劲带动AI服务器出货量攀升,在手订单高涨,关注联想集团、超微电脑、戴尔科技、慧与、工业富联; 5)CoWoS:先进封装CoWoS产能成AI算力供应瓶颈,台积电订单持续外溢,封测厂受益,关注台积电、日月光、Amkor科技; 6)网络:万卡算力集群化趋势驱动通信互联需求,利好光模块、连接器、交换机等,关注中际旭创、新易盛、Coherent、安费诺、Arista网络。 3、建议关注AI应用产业链: 1)云技术服务商:充裕的现金流支持大额资本支出投入,基础设施壁垒高筑,用户基础广阔,关注微软、谷歌、亚马逊、Oracle; 2)AI+开发/数据分析:o1展现出强大的复杂推理和编程能力,对于数据分析、低代码等产品的使用体验提升明显,关注ServiceNow、Palantir、Datadog; 3)AI+网络安全:o1在解决问题的过程中采取了带有攻破性质的解决方法,也体现出了AI辅助网络攻击的潜在威胁。另一方面,基于AI/ML的网络安全解决方案也在不断升级和迭代,AI驱动的网络安全攻防升级将成为未来行业的主旋律。关注致力于AI/ML+网络安全解决方案、拥有较强技术壁垒的的公司,关注微软、CrowdStrike、Fortinet; 4)AI Agent:当前企业客户对AI的数据整合、后台打通、优化工作流的潜在需求较为强劲,o1的技术路径有望加速Agent的发展,大型SaaS公司拥有坚实的客户基础、成熟的销售渠道,特别是专注于ERP、CRM等领域的SaaS产品服务于企业工作流,与Agent的逻辑相契合,关注微软、Salesforce、Workday; 5)AI+教育:o1在复杂问题上具备强大的推理能力和全局思维能力,有望拓展学术教育等垂类应用场景,关注多邻国、Coursera。 4 风险分析 1)AI技术研发和产品迭代遭遇瓶颈:当前AI产业发展较依赖前沿技术突破,若遭遇瓶颈则会导致AI应用需求不足; 2)AI行业竞争加剧风险:当前AI产业链面临激烈竞争,可能因行业竞争加剧而挤压利润空间; 3)商业化进展不及预期风险:AI应用的用户需求和渗透率扩张可能低于预期; 4)国内外政策风险:AI相关版权和数据合规政策仍待完善。 免责声明本订阅号是光大证券股份有限公司研究所(以下简称“光大证券研究所”)海外研究团队依法设立、独立运营的官方唯一订阅号。其他任何以光大证券研究所XX研究团队名义注册的、或含有“光大证券研究”、与光大证券研究所品牌名称等相关信息的订阅号均不是光大证券研究所海外研究团队的官方订阅号。 本订阅号所刊载的信息均基于光大证券研究所已正式发布的研究报告,仅供在新媒体形势下研究信息、研究观点的及时沟通交流,其中的资料、意见、预测等,均反映相关研究报告初次发布当日光大证券研究所的判断,可能需随时进行调整,本订阅号不承担更新推送信息或另行通知的义务。如需了解详细的证券研究信息,请具体参见光大证券研究所发布的完整报告。 在任何情况下,本订阅号所载内容不构成任何投资建议,任何投资者不应将本订阅号所载内容作为投资决策依据,本公司也不对任何人因使用本订阅号所载任何内容所引致的任何损失负任何责任。 本订阅号所载内容版权仅归光大证券股份有限公司所有。任何机构和个人未经书面许可不得以任何形式翻版、复制、转载、刊登、发表、篡改或者引用。如因侵权行为给光大证券造成任何直接或间接的损失股票加杠杆app,光大证券保留追究一切法律责任的权利。 ]article_adlist-->
 海量资讯、精准解读,尽在新浪财经APP
海量资讯、精准解读,尽在新浪财经APP
|
